Maîtrise
statistique des processus multivariés
Avantages et limites des différentes approches sur les
cartes de contrôle multivariées
Nassim Boudaoud & Zohra Cherfi
Laboratoire Conception Qualité Processus et Produit
Université de Technologie de Compiègne
BP 529 - F-60205 Compiègne cedex – France,
Tel : +33 3 44 23 44 23 Fax : +33 3 44 23 52 13
e-mail : Nassim.Boudaoud@utc.fr
RÉSUMÉ. L'objet de cet article est de faire une revue des différentes approches pour la conception de cartes de contrôle multivariées. Nous mettons en avant les avantages et inconvénients des unes et des autres. Enfin, nous proposons des pistes de recherche pour l’amélioration des performances des cartes multivariées.
ABSTRACT. In this paper, we review several
approaches for the design of multivariate control charts, advantages and
drawbacks are presented. Directions of research are proposed to improve the
perfomances of the multivariate charts.
MOTS-CLÉS. maîtrise statistique des processus,
processus multivarié, cartes de contrôle multivairées, identification de
causes.
KEY
WORDS.. statistical
process control, multivariate process, multivariate control charts,
identification of causes
1.
Introduction
La maîtrise de la qualité d'un produit ou d'un processus nécessite généralement la surveillance de plusieurs caractéristiques qui peuvent être interdépendantes et/ou corrélées ( cf. Figure 2). Généralement, pour réaliser le contrôle de plusieurs caractéristiques on utilise autant de cartes de contrôles (Shewhart) que de mesures. L'hypothèse implicite est l'indépendance des caractéristiques, hypothèse qui peut parfois ne pas être vérifiée. Ce type d'approche ne prend pas en compte la corrélation possible entre les différentes caractéristiques.
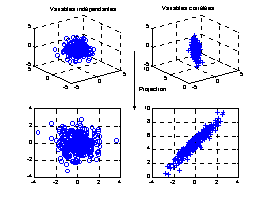
Figure 1 :
Exemple de caractéristiques indépendantes et
corrélées
Cette approche est peu efficace
lorsque les caractéristiques sont corrélées (cf. Figure 2). La probabilité de
fausse alarme globale est différente des niveaux de fausse alarme fixés pour
chaque carte. En effet, si a
est la probabilité de fausse alarme associée à une caractéristique et que les
caractéristiques sont supposées indépendantes, alors la probabilité de fausse
alarme sur l'ensemble de M caractéristiques individuelles est : ![]()
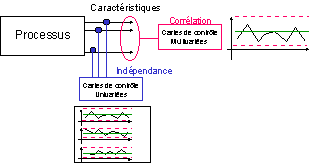
Figure 2 : Maîtrise statistique d’un processus multivarié
Dans le cas où les caractéristiques sont corrélées le calcul de la probabilité de fausse alarme est plus fastidieux [Mon 91].
Afin de maîtriser la probabilité de fausse alarme globale, on préconise généralement l'utilisation de cartes de contrôle multivariées basées sur l'une des statistiques suivantes : c2, T2 [Hot 47], [Jac 85] et [Tra 92]. Le c2 est généralement utilisé lorsque la matrice de covariance et la moyenne du vecteur caractéristique sont connues à priori. A défaut, ces dernières sont estimées sur un échantillon de référence et alors on utilise la statistique du T2.. [Jai 93] dans l'une de ses publications propose une approche Bayesienne multivariée.
Pour la détection de changements de faible amplitude, les cartes CUSUM multivariées [Woo 85], [Cro 88] et EWMA multivariées [Low 92] sont les plus adaptées. Une étude comparative de ces différentes approches est présentée par [Wie 94].
L'une des principales difficultés d'utilisation des cartes multivariées est le problème d'identification de la variable (des variables) mise(s) en cause lorsqu’un signal hors contrôle est détecté.
Lorsqu’un signal généré par le T2 dépasse les limites de contrôle (déviation anormale), il s'agit d'identifier la caractéristique ou l’ensemble des caractéristiques à l'origine du déréglage. Dans le cas où le processus n'est plus sous contrôle, l'approche multivariée ne permet pas la localisation de la caractéristique hors contrôle. De nombreux travaux ont été réalisés proposant des solutions pour l'identification de la variable ou de l'ensemble des variables ayant contribué à un déréglage.
Certains auteurs proposent l'utilisation des cartes de contrôle univariées relatives aux caractéristiques ou à leurs composantes principales [Jac 56], [Jac 59], [Jac 85], [Alt 85] et [Hayter 94]. Les travaux réalisés ces dix dernières années portent sur différentes formes de décompositions de la statistique de Hotelling [Mur 87], [Haw 93], [Mas 95] et [Mas 99]. Des outils de visualisation ont également été proposés pour la représentation graphique des cartes de contrôle multivariées : ``Polyplot'' (représentation simultanée des moyennes individuelles et du vecteur moyenne correspondant), ``Chernoff faces'', ``Profiles'' (représentation de chaque variable sous forme d'un histogramme) et "Line-Graph" (représentation simultanée de la statistique de Hotelling et des p-variables d'observation). Ces différentes formes de représentation ont été comparées par Subramanyam [Sub 95] elles constituent des outils d'aide au diagnostic.
Dans cet article nous faisons une revue des différentes approches proposées pour l'identifications des caractéristiques mises en cause lors d'un déréglage. Nous proposerons des directions de recherches pour contribuer à l’amélioration de ces méthodes.
2. Revue des différentes approches
2.1 Introduction
La statistique du T2 a été introduite par [Hot 47], elle permet la surveillance de la qualité globale d'un produit dépendant de plusieurs caractéristiques.
Dans le cas de mesures individuelles Xi à p caractéristiques, la statistique du T2 est définie comme suit :
![]() [1]
[1]
où ![]() et
et ![]() désignent respectivement le vecteur moyenne (p ´ 1)
et la matrice de covariance (p ´
p). Ces derniers sont estimés à partir d'un échantillon de référence[1]
de taille n :
désignent respectivement le vecteur moyenne (p ´ 1)
et la matrice de covariance (p ´
p). Ces derniers sont estimés à partir d'un échantillon de référence[1]
de taille n :
![]() ,
, ![]() [2]
[2]
En supposant que les n observations sont distribuées selon
une loi normale, la statistique ![]() suit une
distribution de Fisher F(p,n-p;t2)
où
suit une
distribution de Fisher F(p,n-p;t2)
où ![]() . La limite de contrôle supérieure pour un niveau de
confiance globale a est
obtenue à partir de Fa (p,n-p).
. La limite de contrôle supérieure pour un niveau de
confiance globale a est
obtenue à partir de Fa (p,n-p).
Le statistique du T2 peut également être définie dans le cas où les mesures sont recueillies sous forme d’échantillons [Wie 94].
La construction d’une carte multivariée passe en général par deux étapes :
-
La première étape consiste à analyser l’historique du
processus à partir des mesures disponibles. En utilisant les observations
correspondant à un fonctionnement normal du processus, on estime la moyenne![]() et la matrice de covariance S. Puis on établit les limites de contrôle.
et la matrice de covariance S. Puis on établit les limites de contrôle.
- La seconde étape consiste à comparer toute nouvelle observation aux limites de contrôle afin de détecter un possible déréglage, puis à identifier les variables mises en cause ainsi que les causes.
2.2 Identification des variables mises en causes
Nous présentons dans cette partie les différentes approches développées pour l’identification des variables mises en causes lors de la détection d’un signal hors contrôle. On distingue principalement deux approches : la première consiste à décomposer la statistique du T2 dans une base orthogonale, la seconde approche est basées sur une analyse des corrélations entre variables et observations en réalisant une analyse en composantes principale.
2.2.1 Décomposition du T2
La statistique du T2 est utilisée pour la détection d'un processus multivarié hors contrôle, mais ne permet pas la localisation de la variable ou l'ensemble des variables hors contrôle. Une première solution, reprise par différents auteurs, consiste à décomposer cette statistique et à analyser les termes issus de cette décomposition.
[Mur 87] propose d'utiliser
l'écart ![]() , Tk2
étant la statistique du T2
évaluée sur un sous-ensemble k des p variables initiales. L'ensemble des variables initiales est
divisé en sous-ensembles. Murphy propose un test permettant de déterminer parmi
les sous-ensembles celui ou ceux responsables d'un signal hors contrôle. En
pratique cette approche est assez lourde lorsque le nombre de caractéristiques p est grand, la procédure proposée est
menée sur 2p-2
sous-ensembles de variables. Pour être exploitable, on doit avoir un à priori
sur les variables susceptibles d’être mis en cause lors d’un signal hors
contrôle.
, Tk2
étant la statistique du T2
évaluée sur un sous-ensemble k des p variables initiales. L'ensemble des variables initiales est
divisé en sous-ensembles. Murphy propose un test permettant de déterminer parmi
les sous-ensembles celui ou ceux responsables d'un signal hors contrôle. En
pratique cette approche est assez lourde lorsque le nombre de caractéristiques p est grand, la procédure proposée est
menée sur 2p-2
sous-ensembles de variables. Pour être exploitable, on doit avoir un à priori
sur les variables susceptibles d’être mis en cause lors d’un signal hors
contrôle.
[Haw 93] introduit une décomposition utilisant des variables de régression ajustées :
![]() [3]
[3]
où S et ![]() désignent respectivement la matrice de covariance et le
vecteur moyenne du processus sous contrôle. Les composantes du vecteur Z sont
exploitées pour une identification des variables mises en causes. Le problème
est que cette décomposition n’est pas exhaustive et ne permet pas de conclure
dans tous les cas sur les variables mises en cause. Ce résultat est montré par
[Mas 95].
désignent respectivement la matrice de covariance et le
vecteur moyenne du processus sous contrôle. Les composantes du vecteur Z sont
exploitées pour une identification des variables mises en causes. Le problème
est que cette décomposition n’est pas exhaustive et ne permet pas de conclure
dans tous les cas sur les variables mises en cause. Ce résultat est montré par
[Mas 95].
Mason, Young et Tracy [Mas 95] proposent une décomposition du T2 permettant d'isoler des caractéristiques mettant en cause un déréglage. En effet, ils proposent une décomposition sous forme de somme de termes quadratiques indépendants ainsi qu’une méthode d'analyse pour l'identification des caractéristiques hors contrôle. Il montrent que cette décomposition est une généralisation de celle proposée par [Mur 87] et [Haw 93]. La décomposition est de la forme suivante :
![]() [4]
[4]
où
![]() [5]
[5]
et la statistique ![]() désigne la jème
composante du vecteur Xi
ajustée par la moyenne et l'écart-type de la distribution conditionnelle de Xj sachant X1,...Xj-1 notée sj.1,...,j-1 :
désigne la jème
composante du vecteur Xi
ajustée par la moyenne et l'écart-type de la distribution conditionnelle de Xj sachant X1,...Xj-1 notée sj.1,...,j-1 :
![]() [6]
[6]
avec
![]() [7]
[7]
où b’j représente le vecteur de régression, s12 désigne la variance de la composante X1, le vecteur Xi(j-1) comporte l’ensemble des composante du vecteur X à l’exclusion de la composante Xj-1.
La décomposition du T2 n'est pas unique il en existe p!, incluant en tout p(2p-1-1) termes à calculer. Cette décomposition est une somme de termes positifs.
Si T2 est supérieur à la limite de contrôle, il est alors possible de déterminer quel(s) terme(s) contribue(ent) le plus à l'accroissement du T2.
En dimension 2, la statistique du T2 se décompose comme suit :
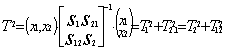 [8]
[8]
avec
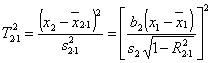 [9]
[9]
La Figure 3 illustre une déviation d’une observation par rapport à la droite de régression (cf. équation [7]). Si cet écart est significatif alors un changement de relation à lieu entre les variables x1 et x2.
En dimension n (n>2), une
valeur significative des Ti2
indique que les variables en question sont en dehors des limites de contrôle.
Une valeur significative des ![]() indique un changement de relation entre les variables en
question par rapport à l'échantillon de référence, cela peut être dû à une
mauvaise estimation de la matrice de covariance ou à une inadéquation du modèle
de régression (cf. équation [7] ). Mason, Young et Tracy [Mas 99] proposent de
substituer les modèles de régression par des formes fonctionnelles issues d’une
connaissance à priori du processus. Ces formes fonctionnelles peuvent être soit
des modèles mathématiques ou issues d’une analyse approfondie des données sur le processus en
fonctionnement normal.
indique un changement de relation entre les variables en
question par rapport à l'échantillon de référence, cela peut être dû à une
mauvaise estimation de la matrice de covariance ou à une inadéquation du modèle
de régression (cf. équation [7] ). Mason, Young et Tracy [Mas 99] proposent de
substituer les modèles de régression par des formes fonctionnelles issues d’une
connaissance à priori du processus. Ces formes fonctionnelles peuvent être soit
des modèles mathématiques ou issues d’une analyse approfondie des données sur le processus en
fonctionnement normal.
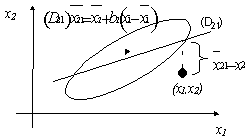
Figure 3 : Représentation des écarts par rapport à la droite de régression (D21)
2.2.2 Analyse en composantes principales
L’analyse en composantes principales (ACP) est utilisée généralement lorsque les caractéristiques mesurées sont fortement corrélées. L'ACP est une projection des variables initiales dans un espace dont les composantes sont orthogonales (indépendantes, non corrélées) et combinaison linéaire des variables initiales.
[Jac 91] propose d’exprimer la statistique T2 en fonction des termes issus d’une décomposition des variables initiales en composantes principales :
![]() [10]
[10]
où les![]() désignent les valeurs propres de la matrice de covariance S et ta
les scores (nouvelles variables) issus de la transformation en composantes
principales.
désignent les valeurs propres de la matrice de covariance S et ta
les scores (nouvelles variables) issus de la transformation en composantes
principales. ![]() représente la
variance des composantes principales. Chaque score s’exprime comme suit :
représente la
variance des composantes principales. Chaque score s’exprime comme suit :
![]() [11]
[11]
où ![]() désigne le vecteur propre correspondant à la valeur propre
désigne le vecteur propre correspondant à la valeur propre ![]()
L’utilisation des composantes principales ( nouvelles variables) pour le suivi du processus ne permet pas de résoudre le problème d'identification des caractéristique(s) mises en causes lorsque le processus est hors contrôle car les nouvelles variables sont combinaison linéaire des variables initiales et n’ont pas forcément une signification physique. Une utilisation différente de l’ACP est proposée par Kourti [Kou 96]. Il préconise une utilisation simultanée des scores et des contributions des variables initiales. Lors de la détection d’un dérégalge, il propose l’investigation des scores normalisés ayant subit une variation significative.
En utilisant l’équation [11], la
contribution globale des variables initiales au score normalisé (ta/sa)2 s’exprime par :
![]() [12]
[12]
On en déduit la contribution d’une variable Xi au score normalisé (ta/sa)2 :
![]() [13]
[13]
Kourti propose d’évaluer la contribution totale de la variable Xj sur les K scores les plus élevés :
![]() [14]
[14]
Avec une condition sur les contributions : une contribution est mise à zéro si son signe est négatif (son signe est opposé au signe du score ta). On ne considère que les variables corrélées positivement au score (contribuant à l’accroissement du score).
Lorsqu’un signal hors contrôle est détecté sur la statistique du T2 on recherche l’ensemble des scores en dehors des limites de contrôle (±3s). On calcule ensuite pour l’ensemble des variables la contribution globale à ces scores. Les variables ayant la plus forte contribution sont celles responsables du signal hors contrôle.
Une autre approche est proposée par [Dou 92], elle est basée sur le calcul d’un coefficient d’explication d’une mesure (observation) par une variable (caractéristique). La proximité d’un point mesure et d’un point variable est alors mise en évidence par ce coefficient d’explication. Cet indice permet, lors de la détection d’un signal hors contrôle, d’identifier les variables susceptibles d’être à l’origine du déréglage.
2.2.3 Les limites des différentes approches
Lorsque le nombre de variables est élevé, on est confronté à deux difficultés principales :
- mauvais conditionnement de la matrice de covariance (problème d’inversion),
- augmentation factorielle du nombre de composantes à tester dans le cas d’une décomposition du T2.
L’existence de colinéarité entre les caractéristiques suivies est à l’origine du mauvais conditionnement de la matrice de covariance. Pour y pallier on utilise généralement des méthodes de projection [Kou 96] telles que l’ACP ou la méthode des moindres carrés partiels (PLS). Les caractéristiques initiales sont projetées sur un sous-espace de dimension inférieure engendrant de nouvelles variables indépendantes (combinaison linéaire des variables initiales), et garantissant l’inversion de la matrice de covariance. Ce sont ces nouvelles variables qui sont utilisées pour la surveillance du processus à l’aide de la statistique du T2. Les performances des méthodes de projection sont fortement liées à la représentativité des variables dans l’espace de projection.
Pour le second problème, [Mas 95]
propose d'analyser dans un premier temps les écarts T2-Tj2 pour (j=1,..,p) si pour l'ensemble des caractéristiques les écarts sont
significatifs cela indique que les statistiques conditionnelles ![]() sont mises en cause, il s'agit donc d'analyser ces dernières.
Etant donné le nombre élevé de termes à tester on ne retient dans la phase
d'analyse que les termes ayant subit une variation significative. Notons
toutefois, que cette variation peut avoir deux sources possibles : soit
une inadéquation du modèle de régression, soit un réel changement de structure
de la matrice de covariance. L’analyse exclusive des variations ne permet pas
une discrimination entre les deux sources de variation.
sont mises en cause, il s'agit donc d'analyser ces dernières.
Etant donné le nombre élevé de termes à tester on ne retient dans la phase
d'analyse que les termes ayant subit une variation significative. Notons
toutefois, que cette variation peut avoir deux sources possibles : soit
une inadéquation du modèle de régression, soit un réel changement de structure
de la matrice de covariance. L’analyse exclusive des variations ne permet pas
une discrimination entre les deux sources de variation.
De plus, les différentes approches basées sur la statistique du T2 supposent une distribution multinormale des observations individuelles. Hors, cette condition est en général rarement vérifiée ( illustration Figure 4 ). L’utilisation du T2 dans un contexte où cette condition n’est pas vérifiée engendre une perte d’efficacité de la carte.
Nos recherches bibliographiques ont montré qu’aucune recherche n’a été menée pour la conception de cartes de contrôle multivariées dans le cas où la distribution des mesures est non normale.
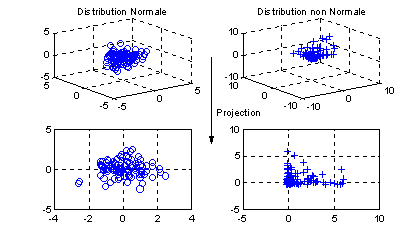
Figure 4 :
Exemple de distribution Normale et non Normale
3. Conclusions et perspectives
Cette revue bibliographique a permis de recenser les différentes approches pour l’identification des variables à l’origine d’un déréglage sur les cartes de contrôle multivariées.
La complexité des procédures proposées, lorsque le nombre de caractéristiques est élevé, rend les cartes de contrôle multivariées difficiles à exploiter dans l’industrie. A cette compléxité, s’ajoute le problème du diagnostic de la cause d’un déréglage. En effet, l’identification des variables ne permet pas le diagnostic direct des causes d’un déréglage. Cela nécessite une analyse approfondie du processus et donc une action corrective différée. Il serait intéressant d’envisager une démarche différente qui consisterait à prendre en compte dans la phase de conception de la carte de contrôle les différents modes de déréglage et les causes associées. En utilisant, par exemple, les données sur l’historique du fonctionnement du processus (normal, déréglage 1, déréglage 2,...). De plus, pour éviter la condition de normalité sur les caractéristiques mesurées, condition nécessaire pour la détermination des limites de contrôle mais rarement vérifiée, on pourrait envisager une approche plus générale en utilisant par exemple des méthodes de classification automatique, de reconnaissance des formes ou les réseaux de neurones artificiels pour la détermination des limites de contrôle entre les différents modes de fonctionnement du processus. Ces pistes de recherche seront développées dans de futurs travaux.
4. Bibliographie
[Alt 85]
F.B. Alt. Multivariate quality control. In Encyclopedia of Stastistical Sciences , 6, 1985.
[Cro 88] R.B. Crosier. Multivariate generalizations of cumulative sum quality control schemes. Technometrics, 30:291--303, 1988.
[Dou 92] M.F. Doutre.
Détection des paramètres générant des rejets dans une production industrielle
après une classification par contour morphologique. XXIV Journées de Statistique, 1992
[Haw
93] D.M. Hawkins. Regression adjustment for variables in multivariate quality
control. Journal of Quality Technology,
25:170--182, 1993.
[Hay
94] A.J. Hayter and K.L. Tsui. Identification and quantification in
multivariate quality control problems. Journal
of Quality Technology, 26:197--208, 1994.
[Hot
47] H. Hotelling. Multivariate quality control--illustrated by the air testing
of bombsights. Technics of Statistical
Analysis, 1947.
[Jac
56] J.E. Jackson. Quality control method for two related variables. Industrial Quality Control, 12, 1956.
[Jac 59]
J.E. Jackson. Quality control method for several related variables. Technometrics, 1, 1959.
[Jac
85] J.E. Jackson. Multivariate quality
control. Communication in Statistics -
Theory and Methods , 14, 1985.
[Jai
93] K. Jain, F.B. Alt, and D. Grimshaw. Multivariate quality control - a
Bayesian approach. In ASQC Quality Congress Transactions, editor, Boston , pages 645--651, 1993.
[Kou 96] T. Kourti and J.F
MacGregor. Multivariate SPC methods for process and product monitoring. Journal
of Quality Technology, 28(4):409—428, 1996.
[Low
92] C.A. Lowry, C.W. Woodall, W.H. Champs, and S.E. Rigdon. A multivariate
exponentially weighted moving average control chart. Technometrics, 34:46--53, 1992.
[Mas
95] R.L. Mason, N.D. Tracy, and J.C. Young. Decomposition of T2 for multivariate control
charts interpretation. Journal of Quality
Technology, 27(2):99--108, 1995.
[Mas
99] R.L. Mason and J.C. Young. Improving the sensitivity of the T2 statistic in multivariate
process control. Journal of Quality
Technology, 31(2):155--164, 1999.
[Mon
91] D.C. Montgomery, Introduction to Statisitcal Quality Control, John Wiley
& Sons, NewYork, 1991
[Mur
87] B.J. Murphy. Selecting out of control variables with the T2 multivariate quality
control procedure. The Statistician,
36:571--583, 1987.
[Sub
95] N. Subramanyam and A. Houshmand. Simultaneous representation of
multivariate and corresponding univariate charts using line-graph. Quality Engineering, 7(4):681--692,
1995.
[Tra
92] N.D. Tracy, J.C. Young, and R.L. Mason. Multivariate control charts for
individual observations. Journal of
Quality Control , 24, 1992.
[Woo
85] Woodall, William H., and M. Ncube. Multivariate cusum quality control
procedures. Technometrics, 27, 1985.
[Wie 94]
S.J. Wierda. Multivariate statistical process control –
recent results and directions for future research. Statistica Neerlandica. Vol.
48, n=°2, pp147-168, 1994.