Automne
1998

Automne |
|
| I. LE SIGNAL DE LA PAROLE |
| 1. De l'organe aux sons |
| a. Anatomie des organes phonatoires |

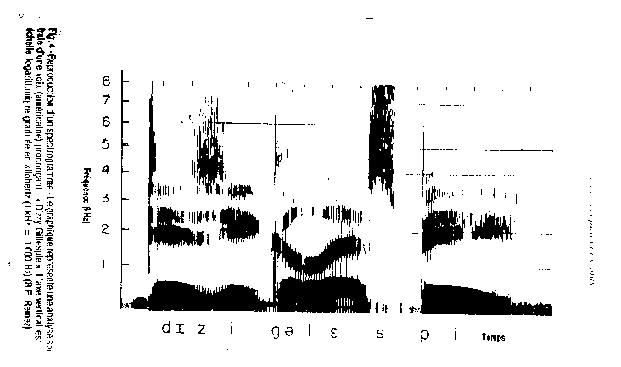
| b. Production du signal de parole (son trŤs ťlaborť) |
| c. Propagation, rťception |
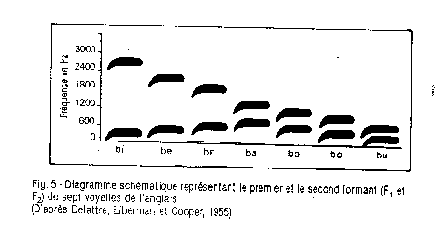
| 2. Les limites de cet outil qu'est la parole |
| a. Cas d'un dysfonctionnement biologique |
| b. Liťes au mileu |
| II. SYNTH…TISEURS VOCAUX |
| 1. L'ťvolution des dispositifs |
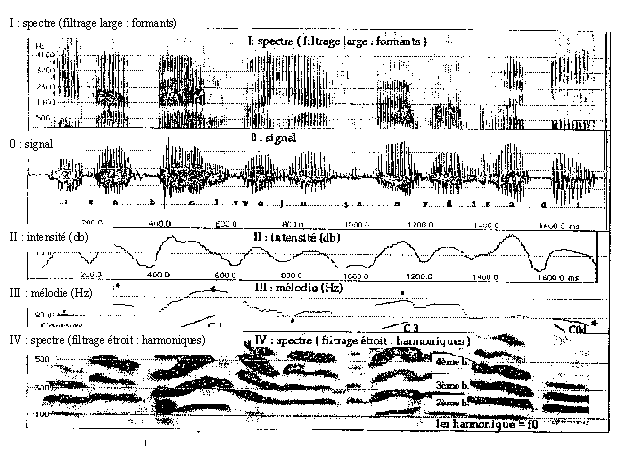
| 2. La prosodie |
| 3. Notre systŤme : le synthťtiseur vocal |
| a. Rappel sur les jauges d'extensomťtrie |
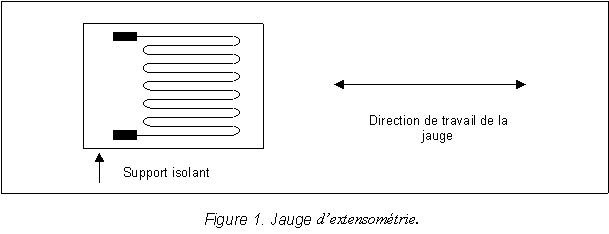
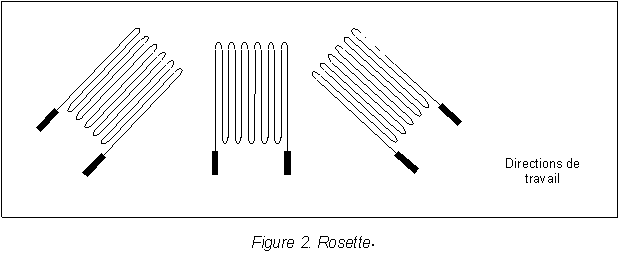
| b. Rťalisation pratique |
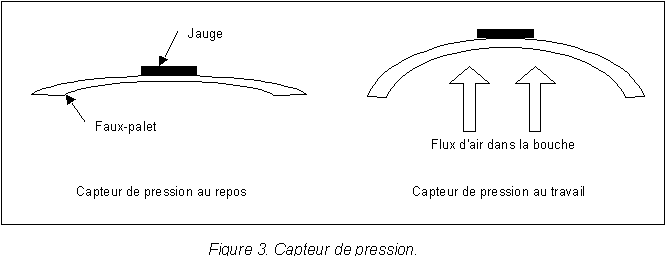
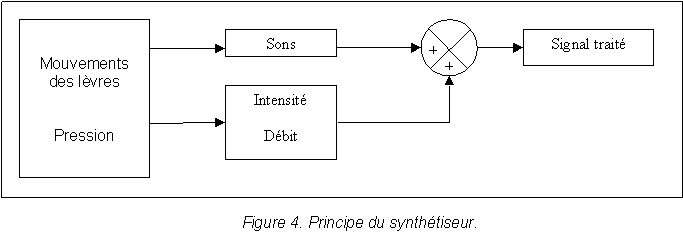
| III. APPLICATIONS DU SYNTHETISEUR |
| 1. Situations possibles |
| 2. Apprentissage |
| 3. Dans le futur |
| CONCLUSION |
| BIBLIOGRAPHIE |